
人工知能の分野は急速な拡大を続けており、大規模言語モデル(LLM)はますます洗練された認知能力を示しています。その中でも、FractalAIResearch/Fathom-R1-14Bは、約148億のパラメータを持つ注目すべきモデルとして登場しました。このモデルは、Fractal AI Researchによって、複雑な数学的および一般的な推論タスクで優れた性能を発揮するように特別に設計されています。Fathom-R1-14Bが際立っているのは、驚くべきコスト効率で、実用的な16,384(16K)トークンのコンテキストウィンドウ内でこの高いレベルのパフォーマンスを達成できることです。この記事では、Fathom-R1-14Bの技術的な概要を提供し、その開発、アーキテクチャ、トレーニングプロセス、ベンチマーク性能を詳細に説明し、確立された方法に基づいた実践的な実装ガイドを提供します。
Fractal AI: モデルの背後にあるイノベーター

Fathom-R1-14Bは、Fractal AI Researchの製品であり、**インド、ムンバイ**に本社を置く著名なAIおよび分析企業であるFractalの研究部門によるものです。Fractalは、Fortune 500企業に人工知能および高度な分析ソリューションを提供することで世界的な評価を得ています。Fathom-R1-14Bの作成は、人工知能分野におけるインドの高まる野心と密接に連携しています。
インドのAIへの願望
このモデルの開発は、IndiaAIミッションの文脈において特に重要です。Fractalの共同創設者、グループ最高経営責任者、副会長であるSrikanth Velamakanni氏は、Fathom-R1-14Bがより大規模なイニシアチブの初期のデモンストレーションであることを示しました。彼は、「IndiaAIミッションの一環として、インド初の大型推論モデル(LRM)の構築を提案しました...この[Fathom-R1-14B]は、何が可能かを示すほんの小さな証拠にすぎません」と述べ、より大きな700億パラメータバージョンを含む一連のモデルの計画を示唆しました。この戦略的な方向性は、AIの自給自足と国産基盤モデルの創出に対する国家的なコミットメントを強調しています。FractalのAIへのより広範な貢献には、医療支援のためのマルチモーダルAIプラットフォームである**Vaidya.ai**のような他の影響力のあるプロジェクトも含まれます。したがって、Fathom-R1-14Bをオープンソースツールとしてリリースすることは、世界のAIコミュニティに利益をもたらすだけでなく、インドの進化するAIランドスケープにおける重要な成果を意味します。
Fathom-R1-14Bの基盤設計とアーキテクチャの青写真
Fathom-R1-14Bの印象的な能力は、慎重に選ばれた基盤と、推論タスクに最適化された堅牢なアーキテクチャ設計の上に構築されています。
Fathom-R1-14Bの開発は、ベースモデルとしてDeepseek-R1-Distilled-Qwen-14Bを選択することから始まりました。このモデルの「蒸留された(distilled)」性質は、より大きな親モデルから派生した、よりコンパクトで計算効率の高いモデルであることを意味しており、特に評価の高いQwenファミリーの能力の大部分を保持するように特別に設計されています。これは強力な出発点となり、その後Fractal AI Researchは専門的な後処理技術によって綿密に強化しました。その運用には、計算速度と複雑な計算に必要な数値精度との間で効果的なバランスを取る、通常bfloat16(Brain Floating Point Format)精度を使用します。
Fathom-R1-14Bは、Transformerモデルファミリー内の強力なイテレーションであるQwen2アーキテクチャに基づいて構築されています。Transformerモデルは、その革新的な自己注意機構(self-attention mechanisms)により、高性能なLLMの現在の標準となっています。これらの機構により、モデルは出力生成時に、入力シーケンス内の異なるトークン(単語、サブワード、または数学記号)の重要度を動的に重み付けすることができます。この能力は、複雑な数学問題や微妙な論理的議論に存在する複雑な依存関係を理解するために不可欠です。
約148億のパラメータに特徴付けられるモデルの規模は、その性能の鍵となる要素です。これらのパラメータは、ニューラルネットワークの層内の学習された数値であり、モデルの知識と推論能力をエンコードします。このサイズのモデルは、トレーニングデータから複雑なパターンを捕捉し表現するための十分な容量を提供します。
16Kコンテキストウィンドウの重要性
重要なアーキテクチャ仕様は、その16,384トークンのコンテキストウィンドウです。これは、単一の操作で処理できる、入力プロンプトとモデル生成出力の合計の最大長を決定します。一部のモデルははるかに大きなコンテキストウィンドウを誇っていますが、Fathom-R1-14Bの16K容量は、意図的で実用的な設計上の選択です。詳細な問題文、広範なステップバイステップの推論チェーン(オリンピックレベルの数学でしばしば必要とされる)、および包括的な回答に対応するのに十分な大きさです。重要なのは、これは非常に長いシーケンスにおける注意機構に関連する計算コストの二次的な増加を招くことなく達成されており、Fathom-R1-14Bを推論中により機敏でリソース集約的でないものにしています。
Fathom-R1-14Bは本当に、本当にコスト効率が高い
Fathom-R1-14Bの最も印象的な側面の1つは、その後処理プロセスの効率性です。モデルの主要バージョンは、報告されているコストが約499米ドルでファインチューニングされました。この驚くべき経済的実行可能性は、過剰な計算費用をかけずに推論スキルを最大化することに焦点を当てた、洗練された多面的なトレーニング戦略によって達成されました。
この効率的な専門化を支える主要な技術は以下の通りです。
- 教師ありファインチューニング(SFT): この基礎段階では、高度な数学的推論に特化した、高品質で厳選された問題-解答ペアのデータセットでベースモデルをトレーニングしました。SFTを通じて、モデルは正しい問題解決経路と論理的演繹を模倣することを学びました。
- 反復カリキュラム学習(Iterative Curriculum Learning): この戦略では、問題の難易度の全範囲に一度にモデルをさらすのではなく、段階的に課題を導入します。モデルはより単純な数学問題から始め、AIMEやHMMTのようなより複雑な問題へと徐々に移行します。この構造化されたアプローチは、より安定した効果的な学習を促進し、モデルが非常に困難なタスクに取り組む前に強固な基盤を構築することを可能にします。この技術は、重要な前駆モデルである
Fathom-R1-14B-V0.6の開発の中心でした。 - モデルマージング(Model Merging): 最終的なFathom-R1-14Bモデルは、2つの特別にファインチューニングされた前駆モデルの融合です。
Fathom-R1-14B-V0.6(反復カリキュラムSFTを受けたモデル)とFathom-R1-14B-V0.4(「最短チェーン(Shortest-Chains)」でのSFTに焦点を当てたモデルで、おそらく解答の簡潔さを重視)です。わずかに異なる焦点でトレーニングされたモデルをマージすることにより、結果として得られるモデルはより広範な強みを継承します。
この綿密なトレーニングプロセスの全体的な目標は、「簡潔でありながら正確な数学的推論」を植え付けることでした。
Fractal AI Researchは、Fathom-R1-14B-RSという名前のバリアントで代替のトレーニング経路も模索しました。このバージョンは、SFTと並行して、GRPO(Generalized Reward Pushing Optimization)と呼ばれるアルゴリズムを具体的に使用する強化学習(RL)を組み込みました。このアプローチは同等の高いパフォーマンスをもたらしましたが、その後処理コストはわずかに高く、967米ドルでした。両バージョンの開発は、最適な推論パフォーマンスを効率的に達成するための多様な方法論を探求するコミットメントを強調しています。透明性へのコミットメントの一環として、Fractal AI Researchはトレーニングレシピとデータセットをオープンソース化しました。
パフォーマンスベンチマーク: 推論の卓越性を定量化する
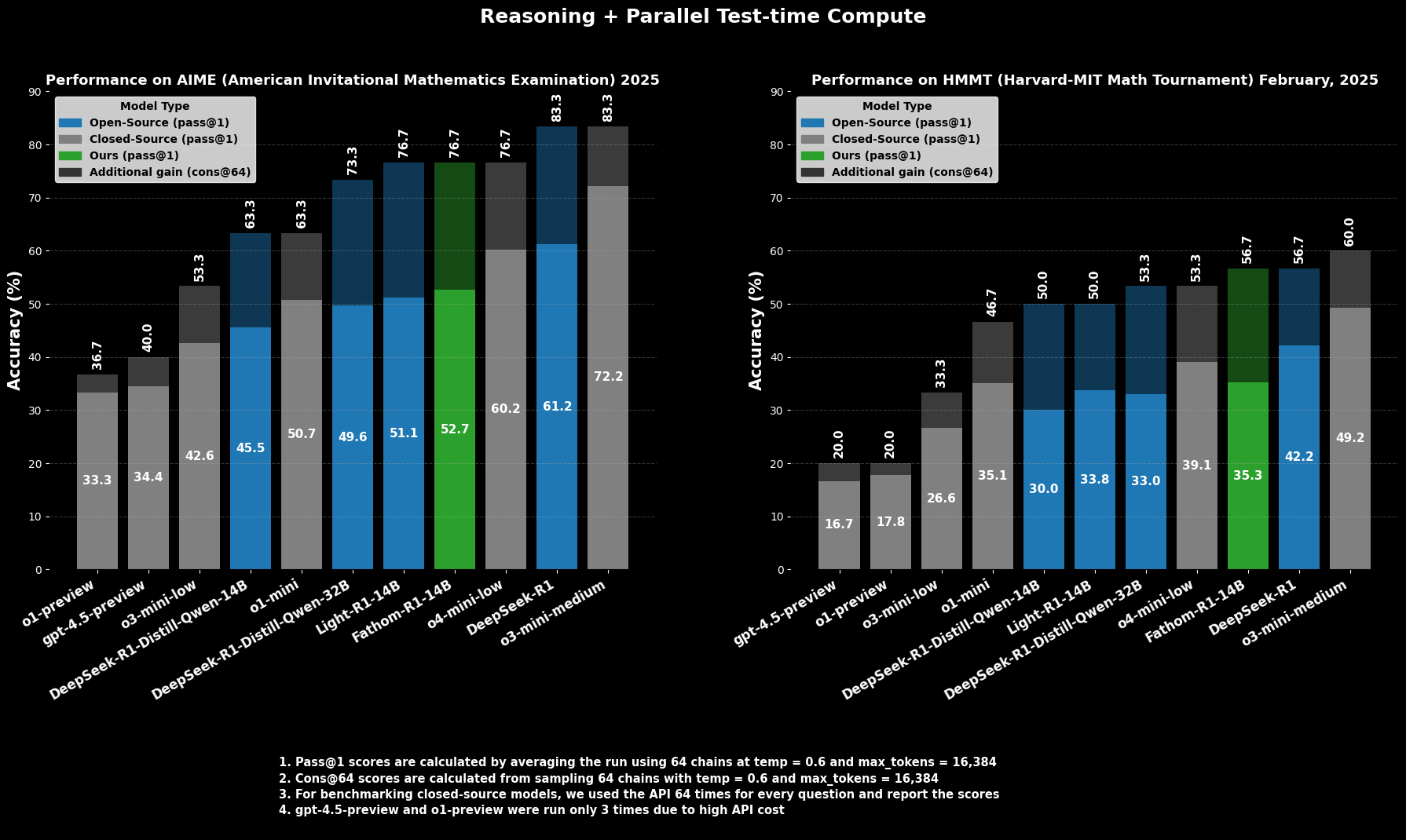
Fathom-R1-14Bの熟練度は単なる理論上のものではなく、厳密な国際的に認知された数学的推論ベンチマークでの印象的なパフォーマンスによって実証されています。
AIMEとHMMTでの成功
難易度の高い大学入学前数学コンテストであるAIME2025(American Invitational Mathematics Examination)において、Fathom-R1-14BはPass@1精度52.71%を達成しています。Pass@1メトリックは、モデルが1回の試行で正しい解答を生成する問題の割合を示します。テスト時に計算バジェットを増やし、cons@64(64個のサンプリングされた解答間の一貫性)を使用して評価した場合、AIME2025での精度は印象的な76.7%に上昇します。
同様に、別の高レベルコンテストであるHMMT25(Harvard-MIT Mathematics Tournament)では、モデルはPass@1で35.26%を記録し、cons@64では56.7%に増加します。これらのスコアは、モデルの16Kトークン出力バジェット内で達成されており、実用的なデプロイメントの考慮事項を反映しているため、特に注目に値します。
比較パフォーマンス
比較評価において、Fathom-R1-14Bは、これらの特定の数学ベンチマークにおけるPass@1で、同等またはそれ以上のサイズの他のオープンソースモデルを大幅に上回っています。さらに驚くべきことに、特にcons@64メトリックを考慮した場合、そのパフォーマンスは、しばしばはるかに大きなリソースにアクセスできると推定される一部の有能なクローズドソースモデルと競争力がある位置にあります。これは、Fathom-R1-14Bがそのパラメータとトレーニングを高精度な推論に変換する効率性を強調しています。
Fathom-R1-14Bを実行してみましょう
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
このセクションでは、Python環境内でHugging Faceのtransformersライブラリを使用してFathom-R1-14Bを実行することに焦点を当てたガイドを提供します。このアプローチは、ローカルまたはクラウドプロバイダーを通じて高性能なGPUハードウェアにアクセスできるユーザーに適しています。ここで概説する手順は、このようなモデルをデプロイするための確立されたプラクティスに密接に従っています。
環境設定
適切なPython環境をセットアップすることが重要です。以下の手順は、Linuxベースのシステム(またはWindows Subsystem for Linux)でCondaを使用する一般的なセットアップを詳述しています。
マシンへのアクセス: リモートのクラウドGPUインスタンスを使用している場合は、SSH経由で接続します。Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key\nGPU認識の確認: システムがNVIDIA GPUを認識し、ドライバーが正しくインストールされていることを確認します。Bash
nvidia-smi\nConda環境の作成とアクティベート: プロジェクトの依存関係を分離することは良い習慣です。Bash
conda create -n fathom python=3.11 -y\nconda activate fathom\n必要なライブラリのインストール: PyTorch(CUDAバージョンと互換性のあるもの)、Hugging Faceのtransformers、accelerate(効率的なモデルのロードと分散のため)、notebook(Jupyter用)、およびipywidgets(ノートブックのインタラクティブ性のため)をインストールします。Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit\n# Example for CUDA 11.8:\n# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118\n# Or for CUDA 12.1:\npip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121\n\nconda install -c conda-forge --override-channels notebook -y\npip install ipywidgets transformers accelerate\nJupyter NotebookでのPythonベース推論
環境が準備できたら、Jupyter Notebookを使用してFathom-R1-14Bをロードし、操作できます。
Jupyter Notebookサーバーの起動: リモートサーバーにいる場合は、リモートアクセスを許可し、ポートを指定してJupyter Notebookを起動します。Bash
jupyter notebook --no-browser --port=8888 --allow-root\nリモートで実行している場合、Jupyterインターフェースにアクセスするために、ローカルマシンからSSHポートフォワーディングを設定する必要があるでしょう。Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip\nその後、ウェブブラウザでhttp://localhost:8889(または選択したローカルポート)を開きます。
モデル操作のためのPythonコード: 新しいJupyter Notebookを作成し、以下のPythonコードを使用します。Python
import torch\nfrom transformers import AutoModelForCausalLM, AutoTokenizer\n\n# Define the model ID from Hugging Face\nmodel_id = "FractalAIResearch/Fathom-R1-14B"\n\nprint(f"Loading tokenizer for {model_id}...")\ntokenizer = AutoTokenizer.from_pretrained(model_id)\n\nprint(f"Loading model {model_id} (this may take a while)...")\n# Load the model with bfloat16 precision for efficiency and device_map for auto distribution\nmodel = AutoModelForCausalLM.from_pretrained(\n model_id,\n torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it\n device_map="auto", # Automatically distributes model layers across available hardware\n trust_remote_code=True # Some models may require this\n)\nprint("Model and tokenizer loaded successfully.")\n\n# Define a sample mathematical prompt\nprompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.\n\nSolution:"""\nprint(f"\nPrompt:\n{prompt}")\n\n# Tokenize the input prompt\ninputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device\n\nprint("\nGenerating solution...")\n# Generate the output from the model\n# Adjust generation parameters as needed for different types of problems\noutputs = model.generate(\n **inputs,\n max_new_tokens=768, # Maximum number of new tokens to generate for the solution\n num_return_sequences=1, # Number of independent sequences to generate\n temperature=0.1, # Lower temperature for more deterministic, factual outputs\n top_p=0.7, # Use nucleus sampling with top_p\n do_sample=True # Enable sampling for temperature and top_p to have an effect\n)\n\n# Decode the generated tokens into a string\nsolution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)\n\nprint("\nGenerated Solution:\n")\nprint(solution_text)\n結論: Fathom-R1-14BがアクセシブルAIに与える影響
FractalAIResearch/Fathom-R1-14Bは、現代のAI分野における技術的な創意工夫の説得力のあるデモンストレーションとして存在します。約148億のパラメータ、Qwen2アーキテクチャ、16Kトークンのコンテキストウィンドウを特徴とするその特定の設計は、画期的でコスト効率の高いトレーニング(主要バージョンで約499ドル)と組み合わされることで、最先端のパフォーマンスを提供するLLMをもたらしました。これは、AIMEやHMMTのような厳しい数学的推論ベンチマークでのスコアによって証明されています。
Fathom-R1-14Bは、AI推論のフロンティアがインテリジェントな設計と効率的な方法論を通じて進歩させることができ、高性能AIがより民主的で広く有益な未来を育むことを説得力をもって示しています。
開発チームが最大限の生産性で協力するための統合されたオールインワンプラットフォームをお探しですか?
Apidogはあなたのすべての要求を満たし、Postmanをはるかに手頃な価格で置き換えます!